Ein kleines Beispiel der Watson Sprachanalyse
Für mich hören sich diese Begriffe wie Sprachanalyse von Watson zwar immer toll an aber irgendwie fehlte mir bisher ein praktisches Beispiel. So ein praktisches Beispiel habe ich heute mal durchgespielt.
Folgendes Szenario: Ein Unternehmen bekommt Liveanfragen aus dem Internet zum Thema Wetter und möchte auf Basis des Textes entscheiden wer der richtige Fachmann zu der Frage ist (Fachbereich 1 / Fachbereich 2). Diese Form der Sprachanalyse kann kaum ein Unternehmen selbst erstellen und betreiben. Aber es könnte einen Plattform as a Service Dienst (Bluemix) nutzen und diesen in seine eigene Anwendung integrieren.
Wir brauchen also ein System, das mir zu einer Frage im Kontext “Wetter” sagt ob es sich zum Beispiel um eine Frage aus dem Bereich Temperatur (Fachbereich 1) oder um eine Frage aus dem Bereich Umweltbedingung (Fachbereich 2) handelt. Dazu gebe ich ein Trainingssets vor und das System soll später zu anderen Fragen, die nicht in dem Trainingsset enthalten sind, mit einer Angabe der Sicherheit (Confidence) sagen ob es sich um eine Frage zu Temperatur oder Umweltbedingung handelt.
Das Bespiel kann hier aus dem Browser heraus ausprobiert werden.
Diese Dokument kann natürlich nicht alle Schritte einer solchen Anwendungsentwicklung beschreiben. Aber es sollen die Schritte beschrieben werden die im Backend (Bluemix) durchgeführt werden müssen und es soll gezeigt werden das man schnell Anfragen stellen und Antworten erhalten kann die man dann weiter in die eigene Anwendung integrieren müsste. Dieses Tutorial beschreibt die Schritte.
Da ich mich auf den Aspekt des maschinellen Lernens und nicht auf die Entwicklung der Oberfläche fokussieren möchte sind die wesentliche Schritte mit dem Programm “Curl” durchgeführt worden. Curl ist ein Linux Kommandozeilenwerkzeug mit dem man Anfragen an einen Webserver senden kann. Die Ergebnisse werden auch im Terminal dargestellt. Im normalen Leben würde man natürlich wie in der Demo noch eine Webanwendung dafür bauen. Das möchte ich mir hier sparen. Das ganze sieht zwar etwas kryptisch oder geekisch aus ist aber eigentlich recht einfach (alos keine Angst haben).
Voraussetzung ist ein (Trial) Account auf Bluemix. Die Schritte sind
- Erstellen des “Natural Language Classifier” Service in Bluemix
- Hochladen und Trainieren der Sprachdaten
- Durchführen der Anfragen
##Schritt 1: Erstellen des “Natural Language Classifier” Service in Bluemix
Wir starten in der Bluemix Startseite und wählen den Katalog
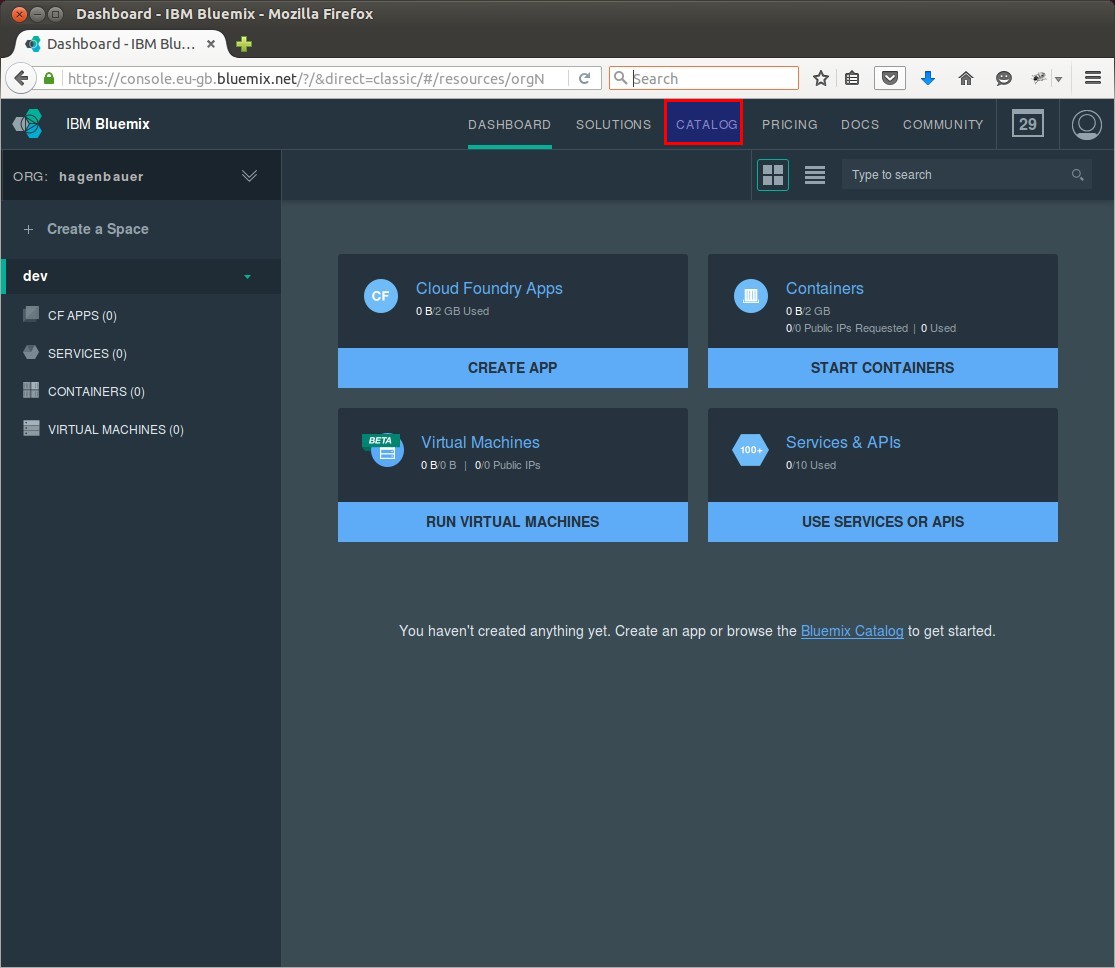
und dort wählen wir den Natural Language Classifier aus
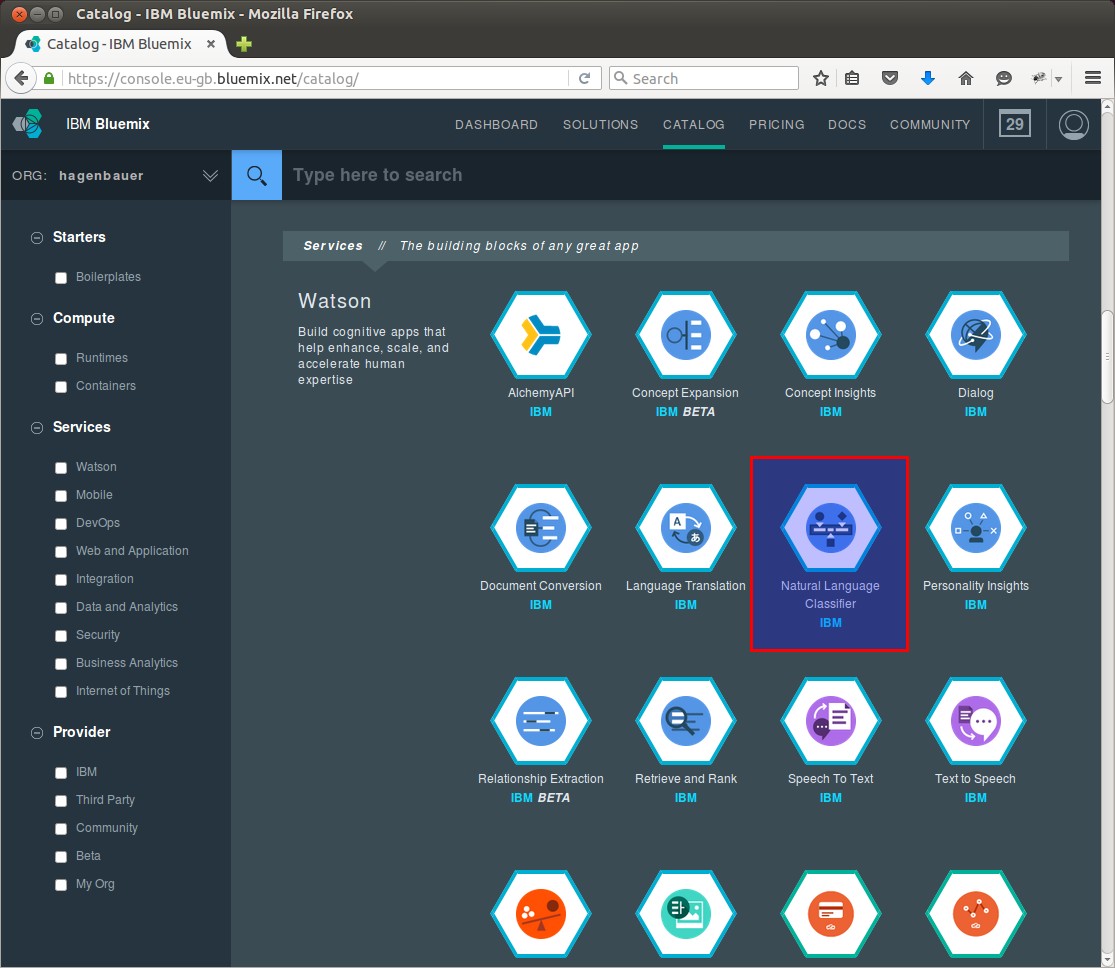
und ändern den Service- und den Credentialname. Die restlichten Daten lassen wir als default
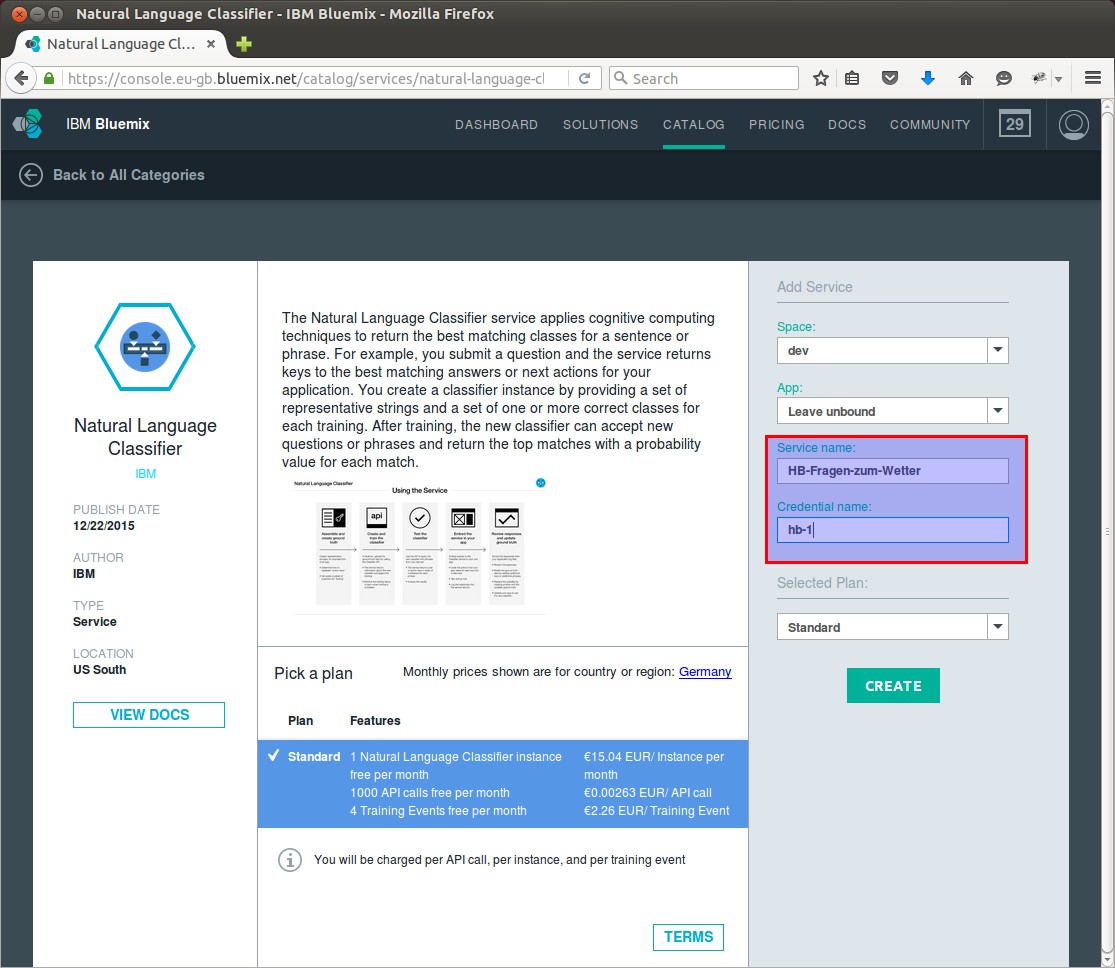
Die Service Credential sind das was wir brauchen und deshalb links in der Navigation auf “Service Credentials”
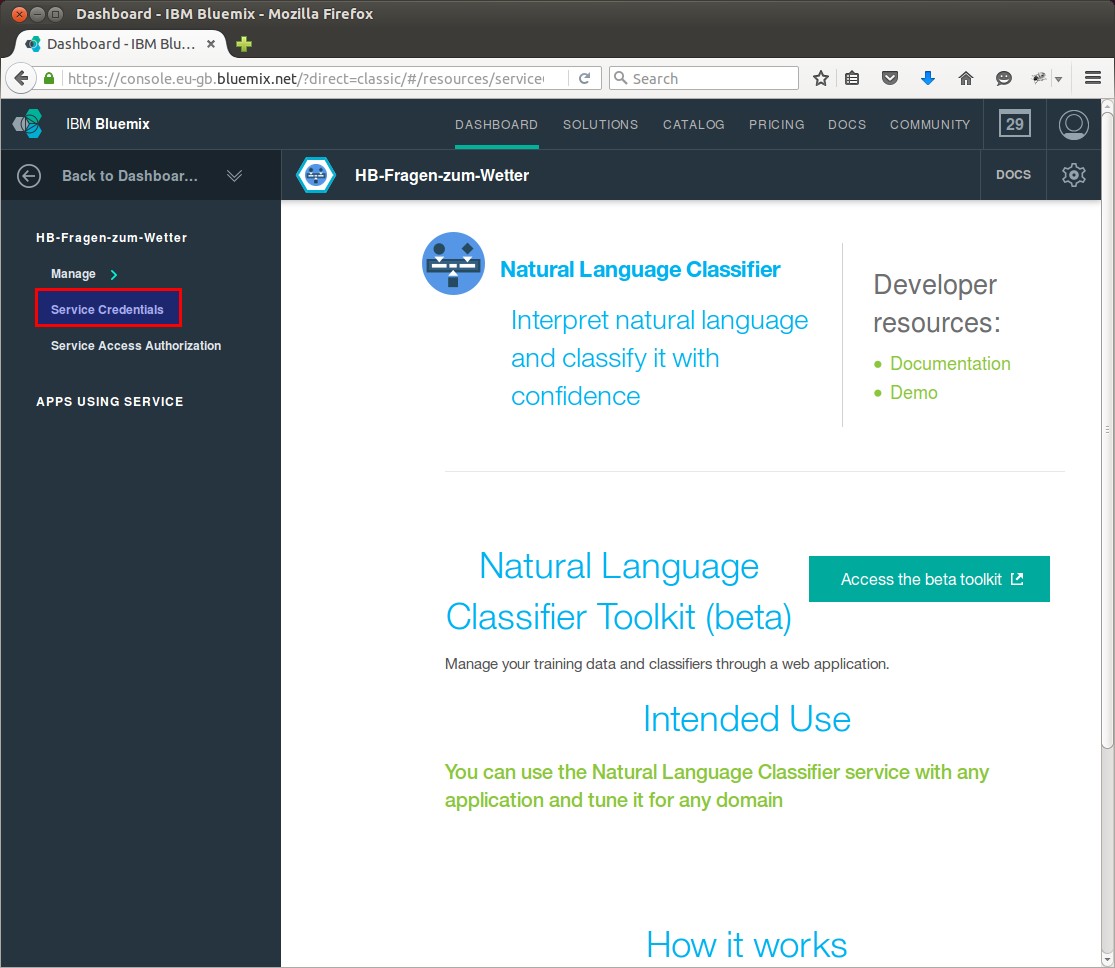
Den Text aus “Service Credentials” kopieren wir uns in den Editor der Wahl.
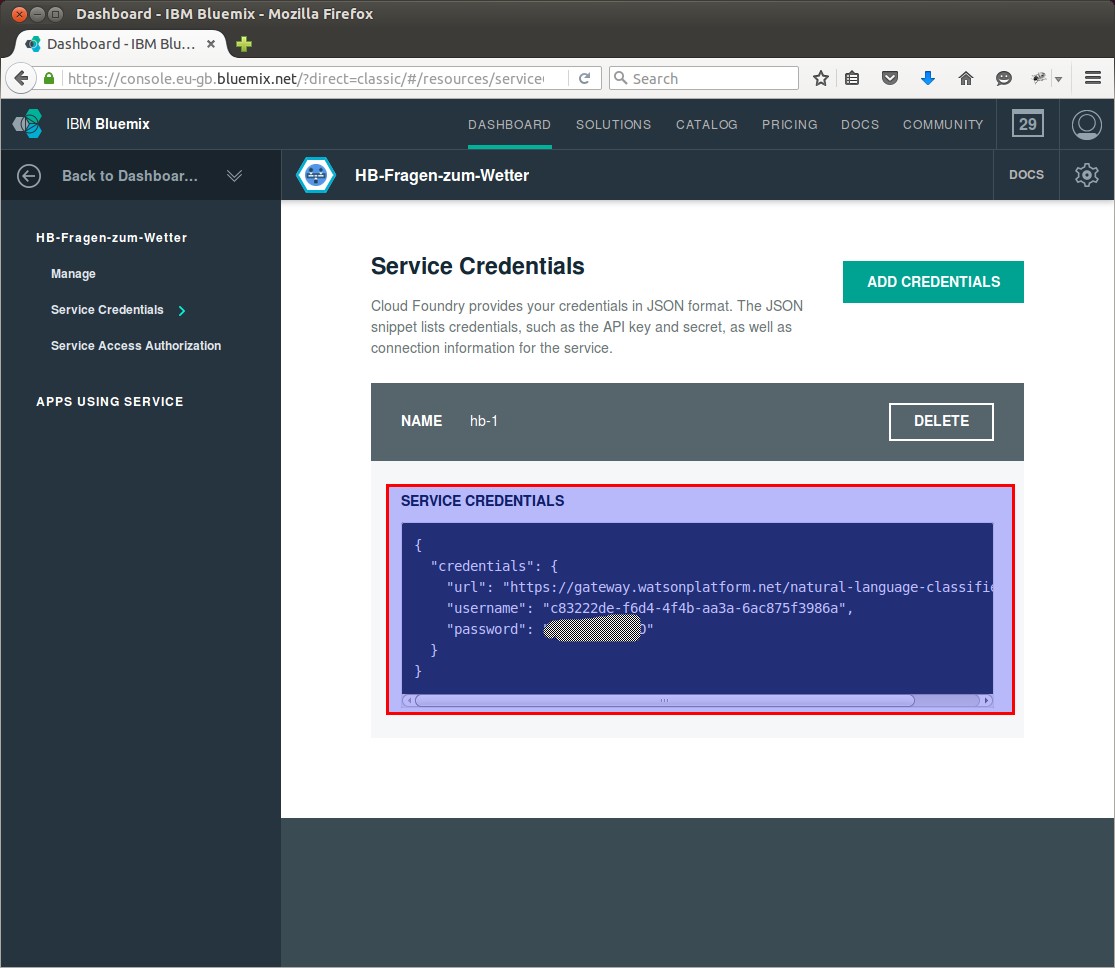
Jetzt haben wir einen Service eingerichtet und die Anmeldedaten bekommen.
Schritt 2. Hochladen und Trainieren der Sprachdaten
Das Trainingssets legen wir “griffbereit” auf der Festplatte ab. Es enthält Beispiele diese Art:
How hot is it today?,temperature
Is it hot outside?,temperature
Will it be uncomfortably hot?,temperature
Will it be sweltering?,temperature
How cold is it today?,temperature
Is it cold outside?,temperature
....
.....
Will it rain today?,conditions
What are the chances for rain?,conditions
Will we get snow?,conditions
Are we expecting sunny conditions?,conditions
Is it overcast?,conditions
Will it be cloudy?,conditions
Jetzt geht es los. Keine Angst es tut nicht weh.
Aus den Credential Daten von Schritt 1 brauchen wir jetzt den Usernamen und das Passwort.
{
"credentials": {
"url": "https://gateway.watsonplatform.net/natural-language-classifier/api",
"username": "Mein-Nutzername",
"password": "Mein-Kennwort"
}
}
Ich habe meine eigenen Werte für die nächsten Schritte in “Mein-Nutzername” und “Mein-Kennwort” geändert. Wenn man die Schritte nachgeht müssen natürliche die eigenen Werte angegeben werden.
Mit diesem Befehl werden die Daten an die richtige Stelle in Bluemix geladen
curl -i -u "Mein-Nutzername":"Mein-Kennwort" \
-F training_data=@/home/hbauer/Desktop/weather_data_train.csv \
-F training_metadata="{\"language\":\"en\",\"name\":\"TutorialClassifier\"}" \
"https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers"
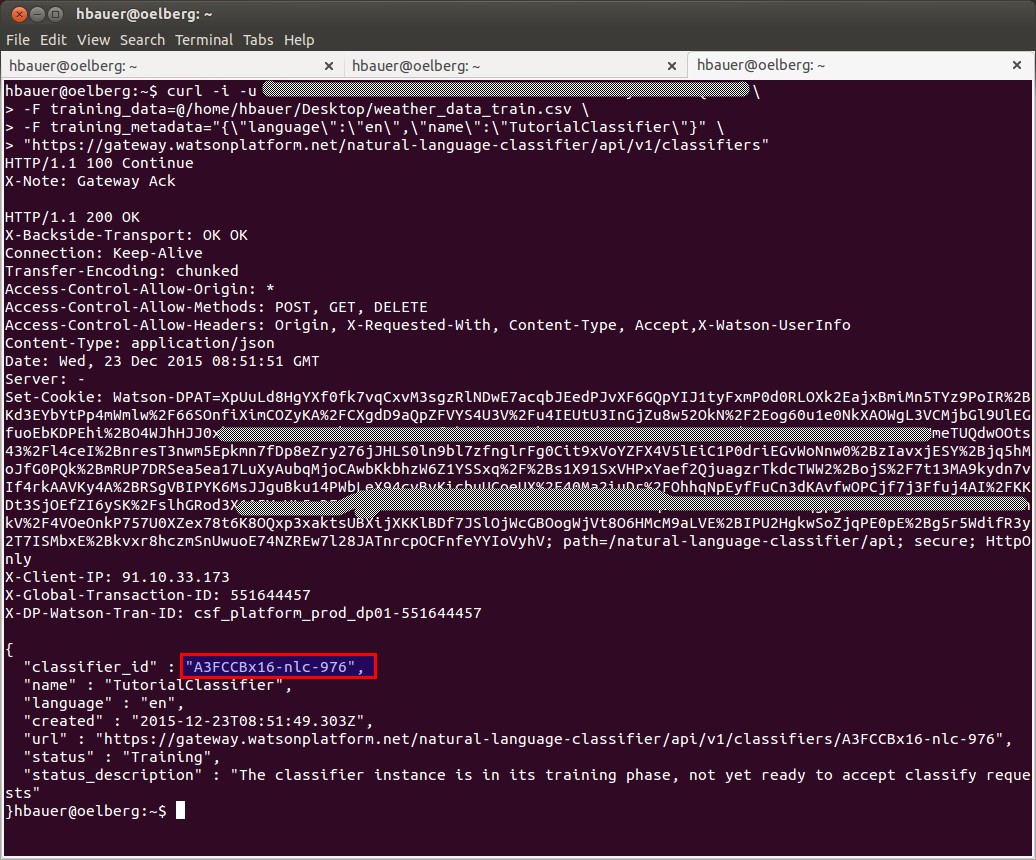
Aus der Antwort ist vor allem die Classifier ID wichtig. Bevor man weitermachen kann muss man erst das Ende der Klassifikation abwarten (ca. 5 Minuten)
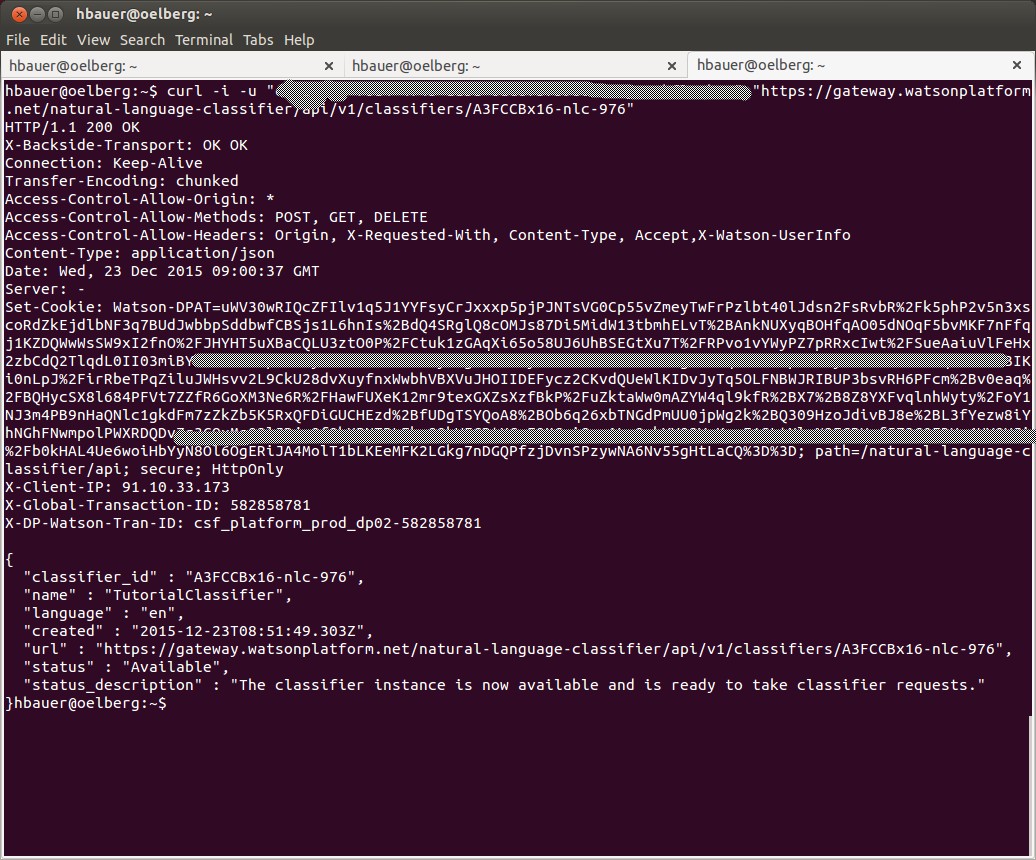
Das war es schon. jetzt kann man Anfragen an Watson stellen.
###Schritt 3: Durchführen der Anfragen
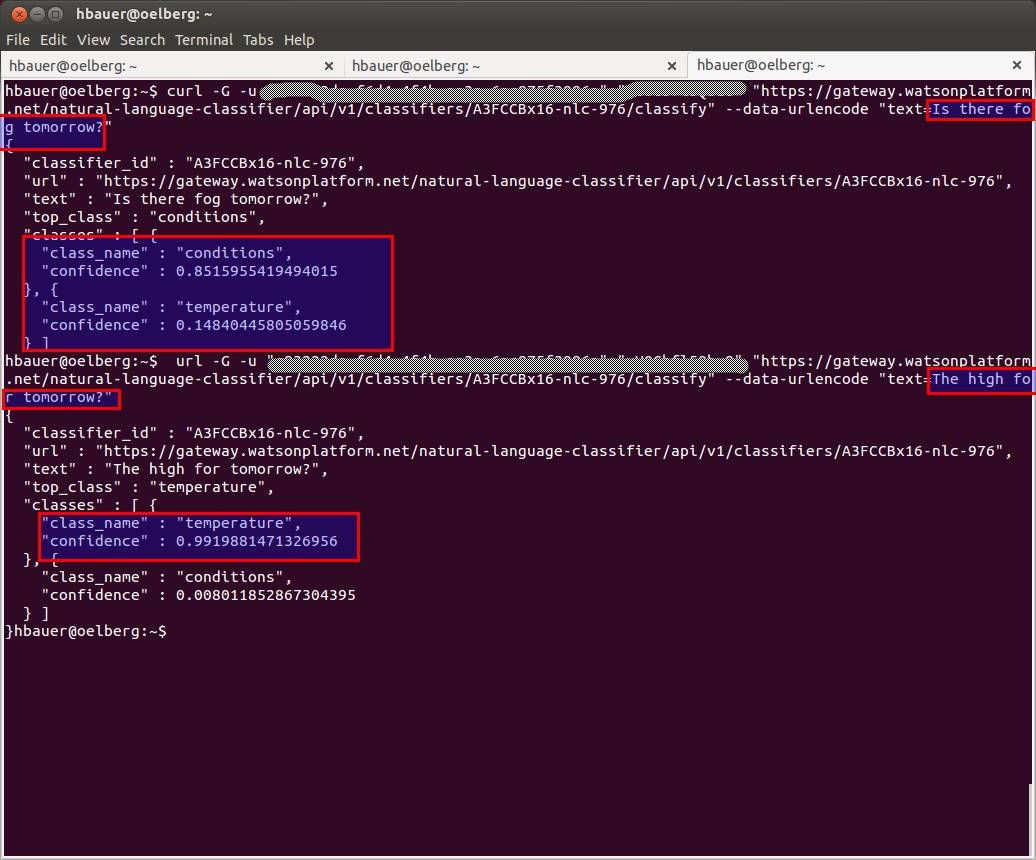
Zuerst starten wir mit zwei einfachen Anfrage aus dem Trainingsset. Und Watson antwortet mit einer “ziemlich hohen” Sicherheit ( 0.992900184501599) in welche Kategorien die Anfragen fallen.
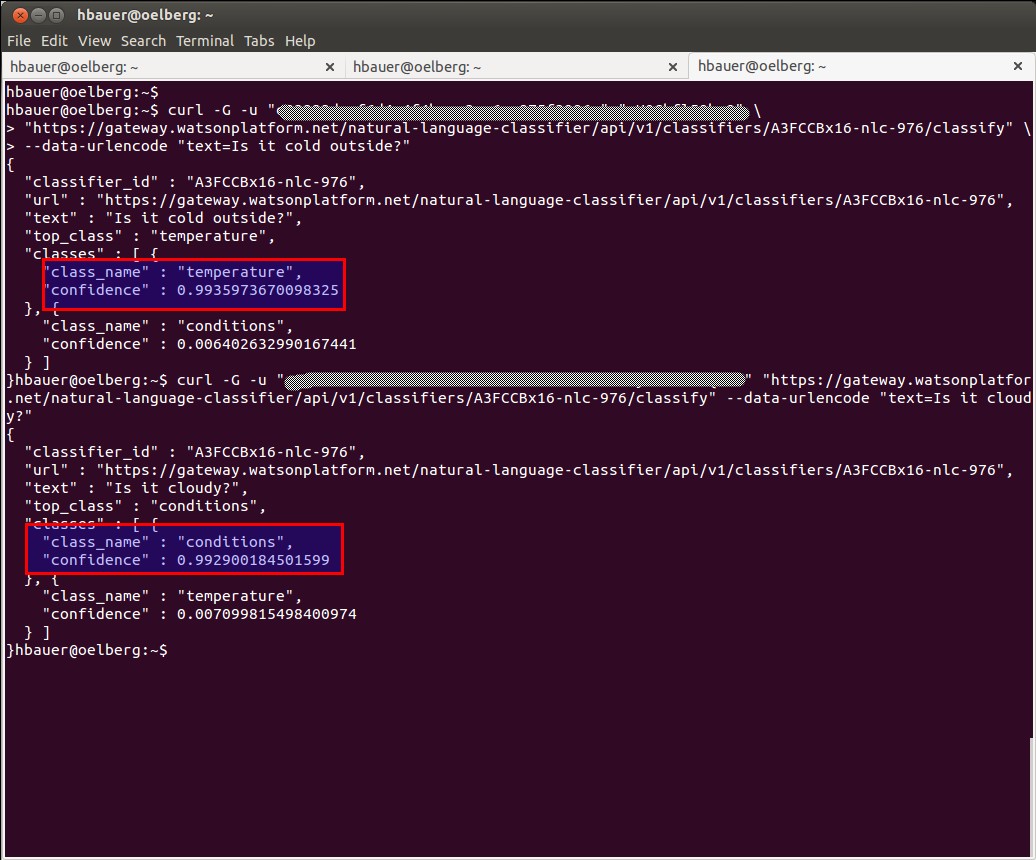
Jetzt zwei Anfragen die nicht im Trainingsset vorkamen. Wir fragen nach
- Foggy (Wort ist nicht im Trainingsset)
- high tomorrow (Satz ist nicht im Trainingsset)
Watson antwortet richtig aber mit einer niedrigeren Sicherheit.
###Fazit
Das war natürlich nur ein kleines Beispiel wie man schnell mit einem Trainingsset von Texten die Sprachanalysefähigkeiten von Watson mal ausprobieren kann.
Ohne eine Technologie wie Watson als PaaS kann man kaum so etwas in dieser Zeit erstellen und nutzen.